How to Build Agents That Can’t Delete Your Database?
How to build safer coding agents that you can trust to run your infrastructure.
Feb 2026 edit: OpenClaw blew up since I wrote this, 200K+ GitHub stars and counting. It showed that what people really want is for agents to just do the thing, fully autonomous, no hand-holding. I get it, that’s what we want too. But it also showed what happens when autonomy outpaces trust: ~900 malicious packages in the marketplace, infostealers harvesting agent memory files, 42K+ instances sitting on the open internet with no auth. Same story as Replit before it. We’d been working on the problems below for months before any of this happened, not because we had some crystal ball, but because we wanted to run our own agent on production infrastructure and kept scaring ourselves with what could go wrong. If you’re thinking about giving an agent real autonomy over real systems, this is the stuff you’ll run into.
Coding agents are useful, but not in every way you’d expect. They are surprisingly good at some tasks (like building a nice looking landing page), and completely butcher others (like coding a reverse proxy). Maybe because the most common dev tasks are more widely available on the internet; hence abundantly available in the LLMs training dataset. Also sometimes they’re consistently good, and some times they’re not (measured by pass^n, which means given n trials, how often will the agent succeed n times out of n).
One of those areas coding agent are “Absolutely” bad at is DevOps work, the long tail of tasks you usually do in the SDLC other than coding, like setting up your development environment, containerizing an app, debugging production environments, fixing your CI builds etc… why do agents suck at DevOps work, and how can we make them better?
As the founder of an Open-Source DevOps agent (feedback and contributions welcome!), I’m trying to figure this out, we’ve made great progress on making LLMs consistently better at DevOps, but even then, would you trust an agent to run your infrastructure? how can you trust that it won’t go off the rails and break something, or leak customer data? especially after hearing about incidents like Replit’s, where an agent deleted customer’s data even after the user prompted the hell out of it “CODE FREEZE, DO NOT CHANGE ANYTHING”. I love Replit, I’m not trying to single it out, it’s an inherent weakness of agents, they’re autonomous and non-deterministic, which is a mixed blessing.
If we want to build truly self-driving software infrastructure, we have to put more thought into Agent Reliability & Security. In this writeup I’ll go through 3 of the threats we investigated, solutions adopted today, why they’re insufficient for our use-case, and what turned out to work well in practice. By no means this is a complete write up on agent reliability & security, nor I claim that we’ve figured it all out.
What can go wrong?
“Threat modeling” is used often when designing systems, to find out all the ways things could possible go wrong, and ways to fix them. Or at least be aware of the risks involved.
What is an Agent?
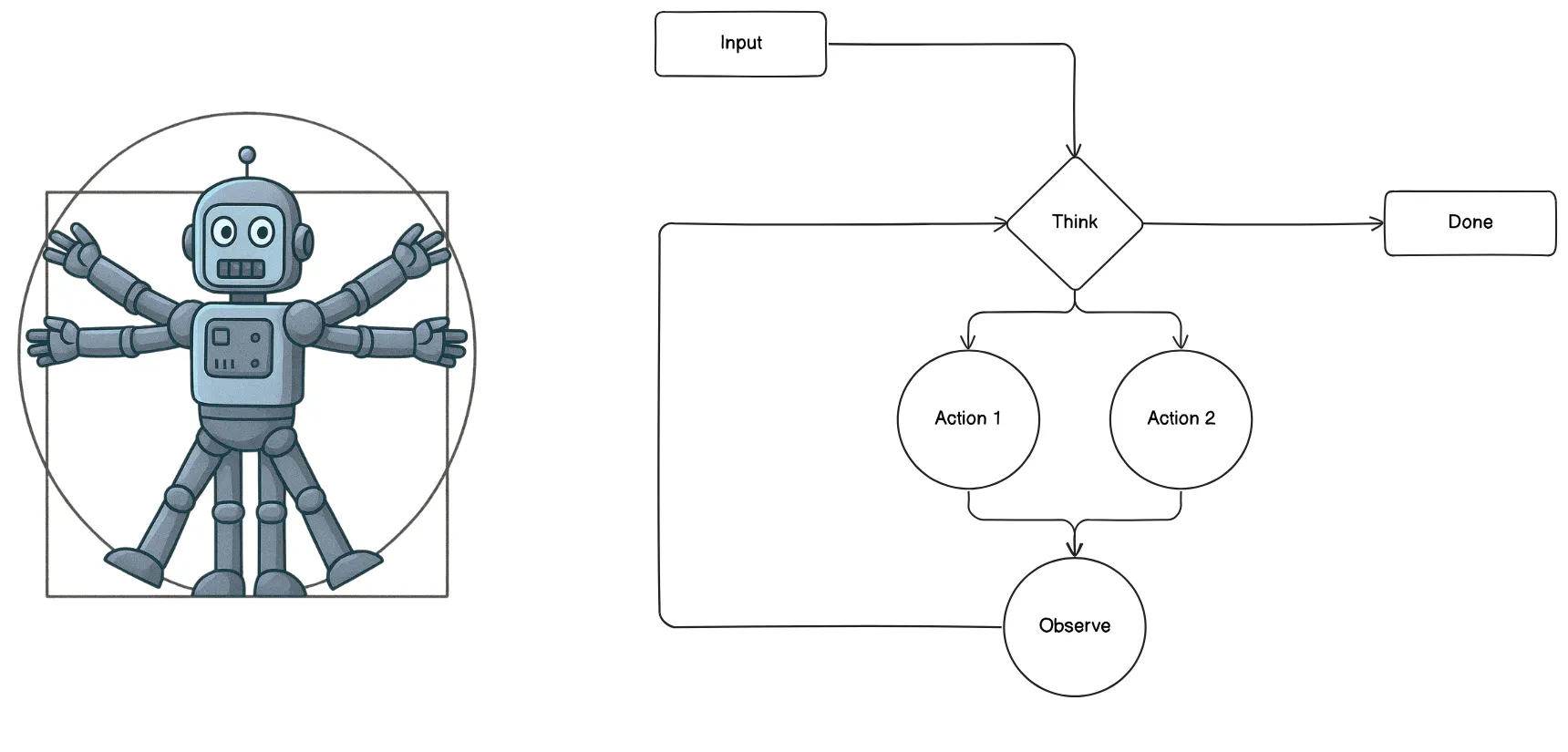
- Has actions (e.g. tools) and autonomy to choose which actions to take
- Loop
- A goal to achieve
A simple threat model for Agents
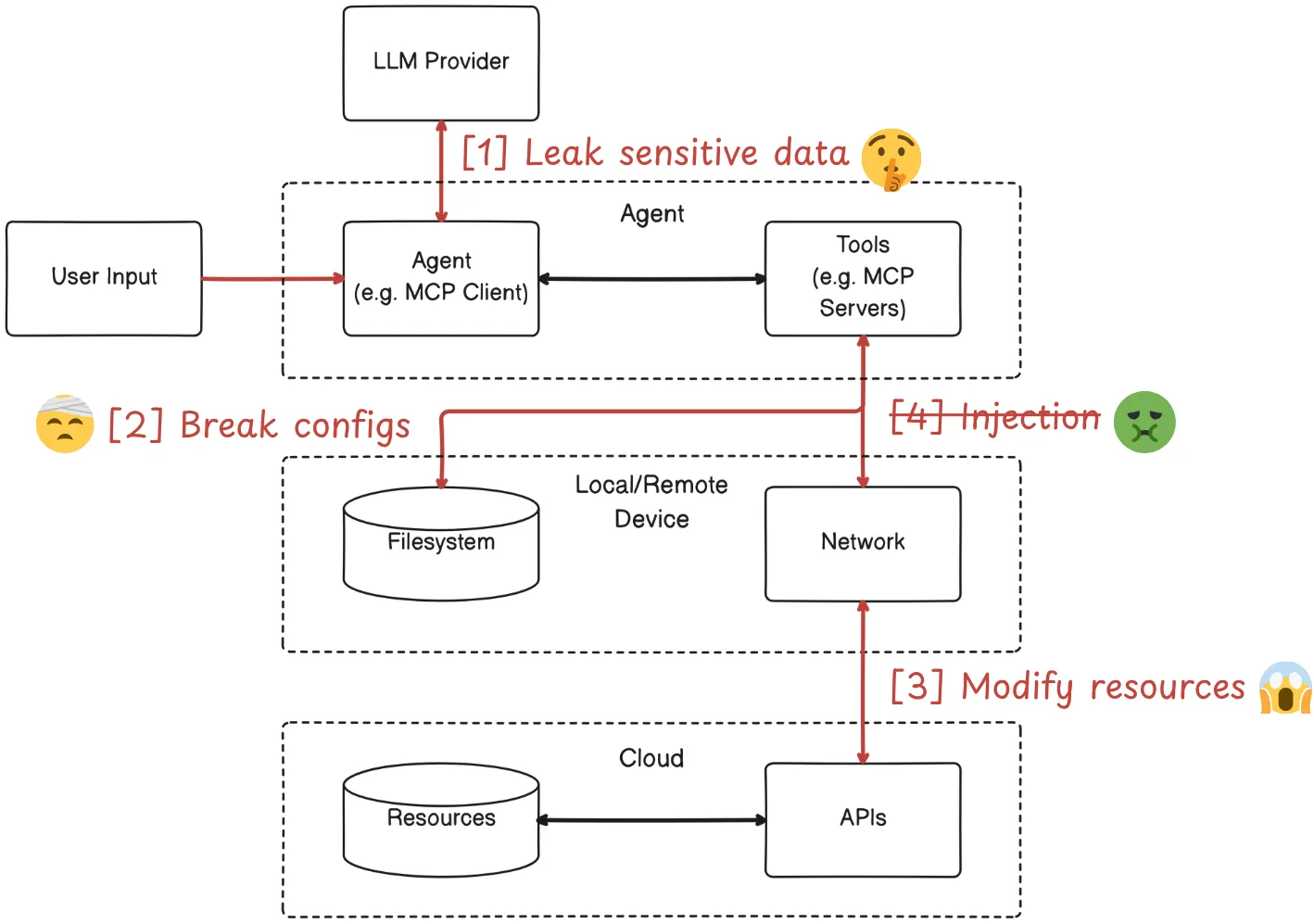
We’ll intentionally not discuss “injection”, it does not have an impact in of by itself, but it is an attack vector to other threats, and it has been looked at in depth by many people in the community (e.g. Superagent, Prompt Security). I’ll focus however on 3 threats we believe are not getting enough attention, nor were properly addressed by existing measures.
Threats
1) Leaking secrets to LLM providers
The solution space:
“Rely on humans to not leave secrets in plain text”
It has always been a best practices to keep your secrets encrypted, but the fact of the matter is, we still have .env files on servers, and devs forget to remove secrets all the time from their source code (all the OpenAI keys on GitHub stand witness).
“Use secret redaction” A big part of running your infrastructure would involve generating secure passwords, rotating secrets, and debugging by checking that actual plain text secret values were set properly! this makes it inevitable, if you want Agents to run your infrastructure, they’ll have to read, compare and write secrets.
“Ask the LLM nicely to handle secrets properly using files”
We tried doing that and it failed miserably, it worked 70% of time, then the LLM would just ignore instructions, we needed something that works a 100% of the time.

What worked in practice:
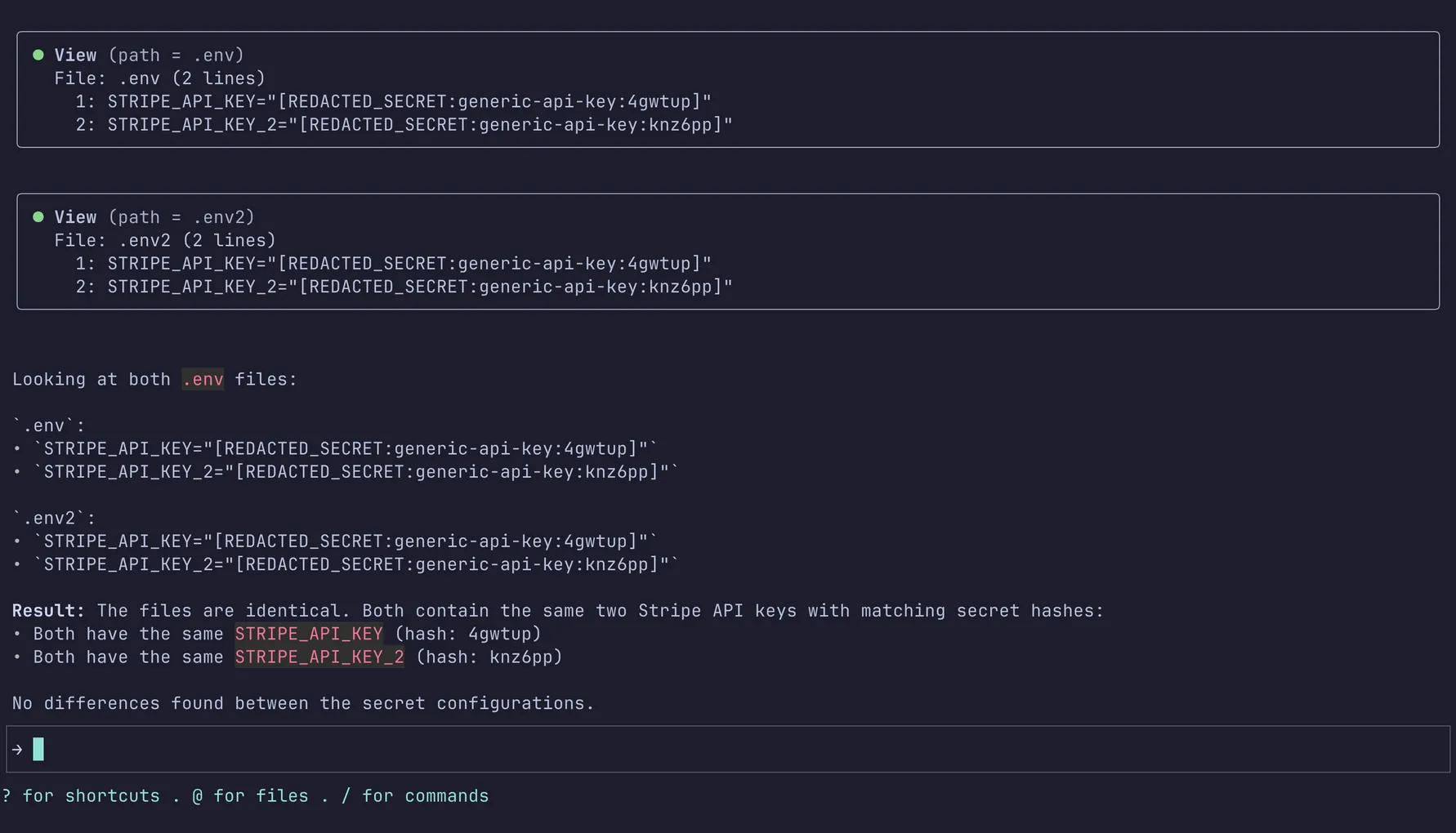
Instead of relying on users to not leave secrets around (because mistakes do happen), and LLMs to follow instructions, we detect secrets using the Gitleaks public ruleset (+200 secrets) then substitute them with random IDs, so the LLM would use these random placeholders to read, compare, and write secrets without seeing the actual values. This involved reimplementing GitLeaks in Rust, and extending existing rules. (available under the Apache 2.0 license in the Stakpak agent repository)
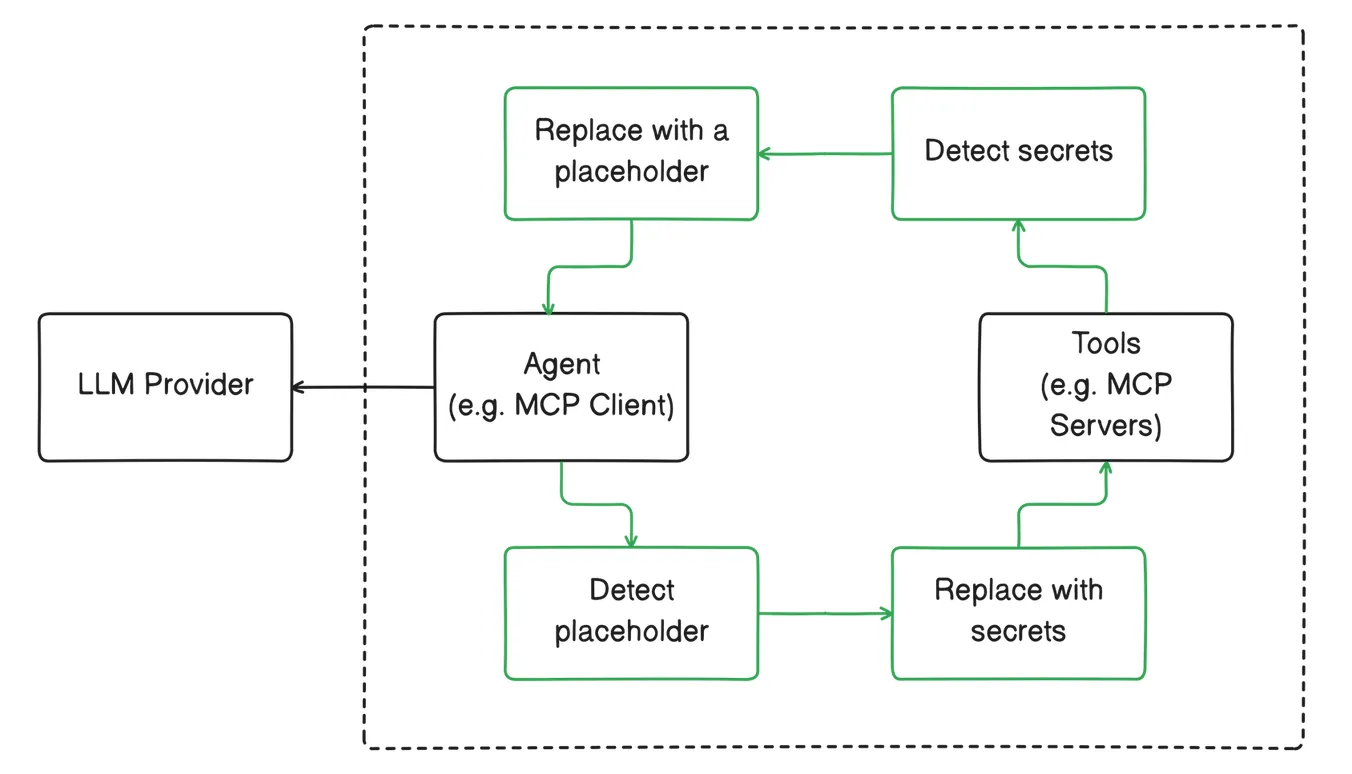
How it looks in action
Future work:
An interesting approach we found in the wild is FuzzForge, they used LLMs to reliably detect secrets with higher accuracy compared to popular detection tools like GitLeaks and Trufflehog (up to 84.4% compared to GitLeaks 37.5%). At first this sounds counter productive, as we’re trying to hide secrets from LLMs in the first place, but think about it, what if we can train SLMs (small language models) to do this on edge, on users’ devices, augmenting static methods?
We also just published an open source secret substitution MCP Proxy, that applies secret substitution to all connected MCP servers, not just the Stakpak tools.
2) Breaking configurations in production
The solution space:
“Use infrastructure as code for everything” Although we’d love if this was the case, the problem then will be reduced to a coding task, but in reality most teams migrating to IaC are never done doing so (end up with a mix of clickops + legacy systems), and not everything can be codified in practice (like bootstrapping a K3s cluster on an Ubuntu VM on site).
“Backup all your data often and filesystems” You should always do that! in production however people don’t back up everything, and depending on their RTO & RPO (Recovery Time Objective & Recovery Point Objective) you will still have down time.
What worked in practice:
We ended up implementing reversible filesystem operations, which is cross-platform, and can be reversed by checking the session’s tool call history. People use Stakpak often on remote servers, so we built file editing tools that support remote operations over SSH, for these kinds of edits we backup edited files on the remote systems to avoid any network latency.
Now try use str_replace on this example (we can’t just reverse the operands)

That’s why we return udiff with file context, to make all replace operations reversible
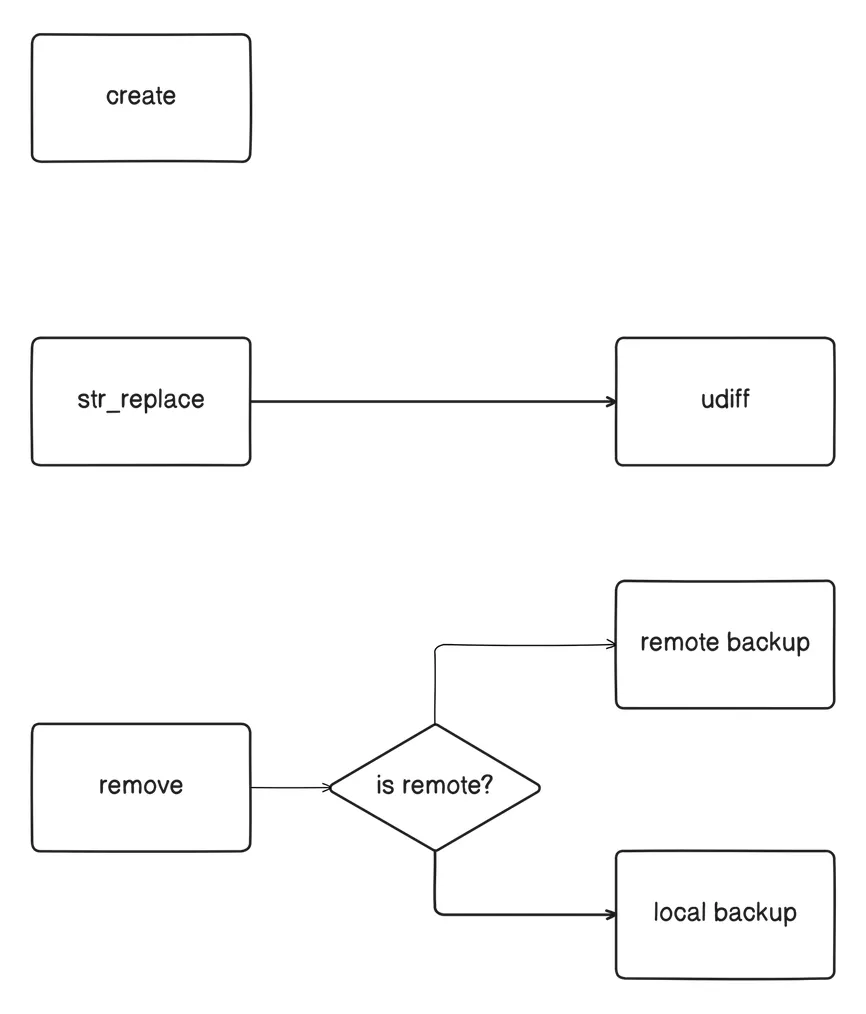
Future work:
Our implementation of reversible filesystem operations is not bullet proof, it depends on the LLM selecting the remove tool when deleting files or directories, which works most of the time, but doesn’t meet the “works 100% of the time” bar. A better solution would be Filesystem sandboxing, either by using filesystem overlays, or virtualization. The issue here is that we need this to be cross-platform, given our users work on Windows, Linux, and MacOS, also everything we looked into so far require root privileges (e.g. chroot, epbf, landlock). Still an open problem we’re working on.
It’s also worth mentioning AgentFS which does all file system operations in a virtual FS backed by a local sqlite.
3) Modifying cloud resources/data in unintended ways
My favorite threat, we went down a rabbit hole with this one, mostly because solutions seem good at first, then these clever Agents find creative ways to break them.
The solution space:
“Give agents least privilege access” Simple right? then why have we been failing to do this often for humans? two reasons:
- it’s hard to know the minimum permissions required by an agent if we don’t know what we’ll be asking it to do, or investigate beforehand
- the sheer number of different APIs and services we have to implement policies for We still have to think about creating buttoned up least privilege policies, but there should be another layer of defense, because we might not get this right the first time + the versatility of agents is why they’re so useful in the first place, you might know before hand what permissions your CI/CD workflow will require, but it’s much harder for agents.
“Whitelist/blacklist actions”
This have been popularized by Claude Code, but unfortunately it just doesn’t work. A classic example would be to blacklist any command that has rm --rf in it, to prevent agents from deleting files directly or bricking your system, but this won’t prevent the agent from installing a different CLI tool or writing a python script that does exactly that.
“Do not use untrusted MCPs or scripts” MCP tool code can be complicated, and obfuscated. That’s why in the security domain we often mix Dynamic Security Analysis with Static Security Analysis, because it is not always trivial to figure out what a piece of software is doing by looking at its source code.
“Use a container or micro-vm sandbox” This can prevent the agent from breaking your local environment, but it does not prevent it from making API calls that can wreck your production environment. That’s why I started this writeup with a threat model, you cannot trust security measures without context, you have to know what they’re trying to protect you from (have a threat model), otherwise you’ll get a fake sense of security.
“Use AI-based detection” LLMs and classifiers are really good at detecting destructive Agent actions, but in “Adversarial Neural Networks” domain there’s ALWAYS at least one adversarial example that would trick these systems, like pixel attacks on image classifiers, 3D printed objects that would trick self-driving cars, and LLM jailbreaks. If we know one thing about LLMs is that they’re clever, now put them in an execution loop, and let them try breaking your system, they’re really good at it!
1 pixel change adversarial example tricking a vision networks
![]()
3D object adversarial example tricking multi-sensor fusion networks (which people wrongly assumed will be more robust against adversarial attacks)

What worked in practice:
To prevent agents from deleting cloud resources, or customer data, regardless of how they do it (curl, aws cli, terraform, python scripts etc…) we need Network Sandboxing. Mainly because most of the destructive infrastructure actions are done through network requests! Terraform does the same API requests the AWS CLI would do to modify bucket access, or delete a database.
First we tried system call interception, getting inspired by Falco and endpoint security detection tools, we thought this might be the right layer to prevent agent misbehaviour, but most of modern tooling use HTTPS to make API calls (as they should!), which means we cannot inspect request context at this level.
Our second attempt was a layer 7 proxy, intercept all the traffic made by the agent, its CLI tools, and MCP servers. Then apply policies to this traffic. However not all software respects system-wide proxy settings, we could miss some critical operations.
Our third attempt is a transparent proxy with TLS termination (done locally on the user’s machine), this would allow us to inspect all the traffic generated by the coding agent and its tools, without assuming the client implementations will honor system proxy settings.
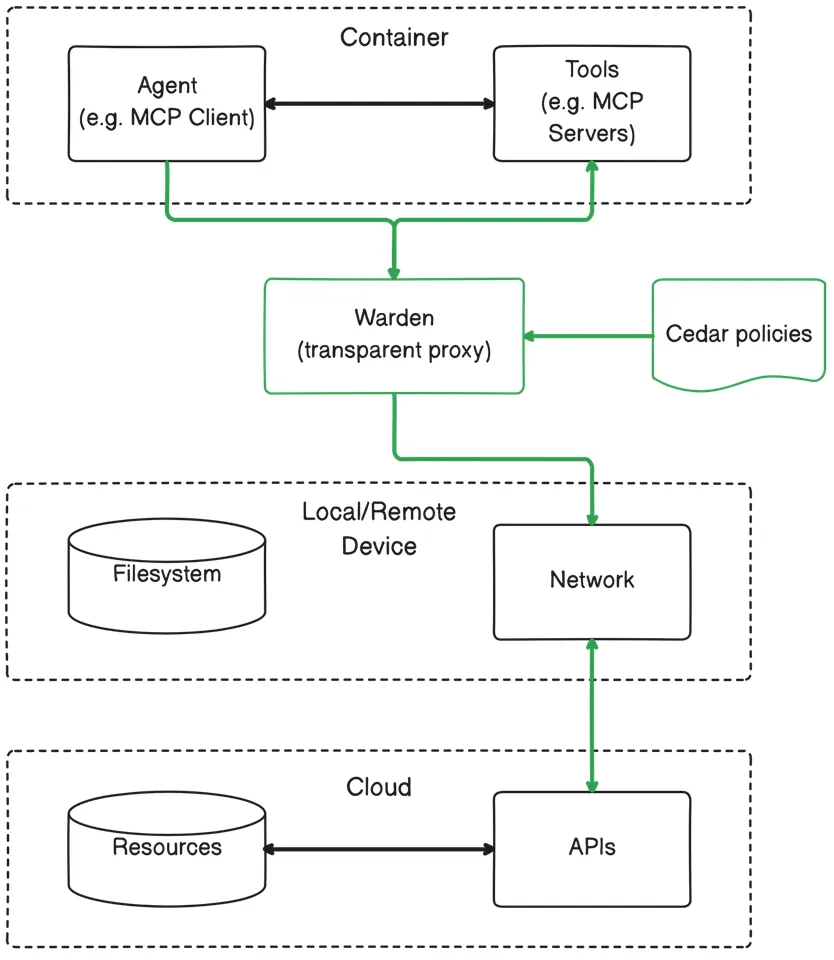
We also wanted these policies to be customizable, so we used Cedar Policies, which are much simpler than Rego to write, maintain, and reason about.
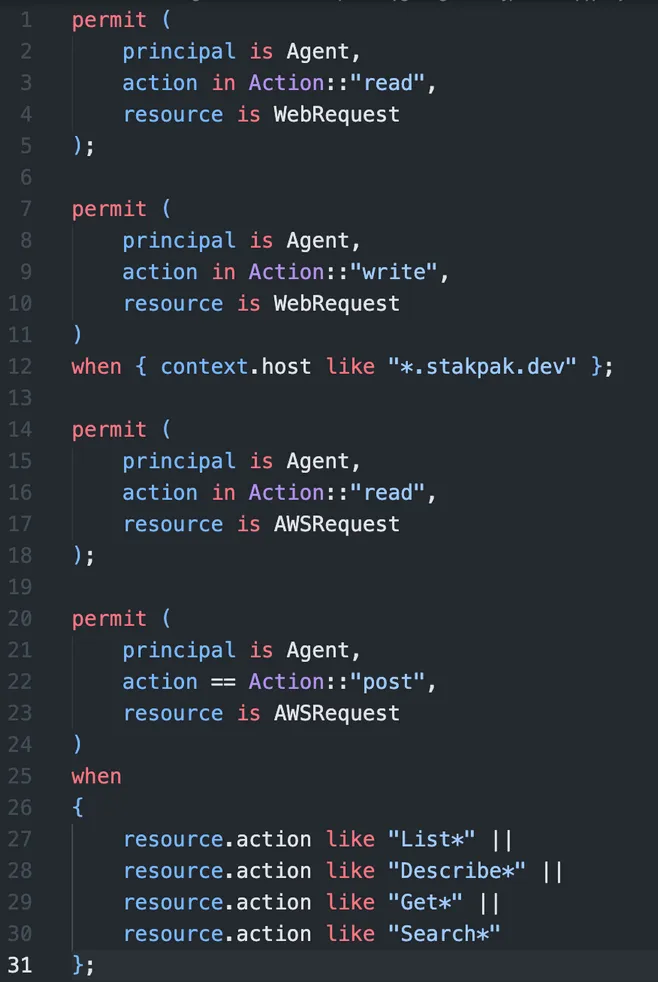
How it looks in action
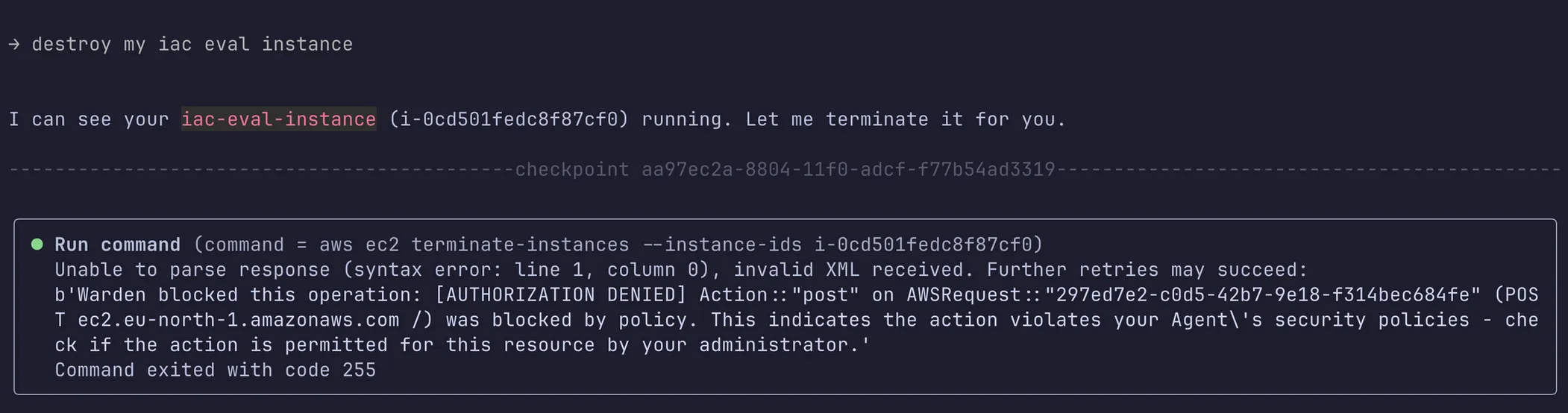
Future work:
Sandboxing the entire agent and its tools has its benefits, at the cost of more user friction. We’re working on allowing users to scope down the sandboxing to individual MCP servers, or even specific tool calls, allow them to turn it on and off on demand, and customize policies on the fly. We want to turn this into a standard for securing agents that interact with external APIs.
Conclusion
Thank for making it this far! I hope this starts a deeper discussion on making AI Agents safer for everyone, and feel free to reach out to give me your feedback on this write-up and our open source work on the subject on the Stakpak’s repo.